1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
|
Metadata-Version: 2.1
Name: stack-data
Version: 0.6.3
Summary: Extract data from python stack frames and tracebacks for informative displays
Home-page: http://github.com/alexmojaki/stack_data
Author: Alex Hall
Author-email: alex.mojaki@gmail.com
License: MIT
Classifier: Intended Audience :: Developers
Classifier: Programming Language :: Python :: 3.5
Classifier: Programming Language :: Python :: 3.6
Classifier: Programming Language :: Python :: 3.7
Classifier: Programming Language :: Python :: 3.8
Classifier: Programming Language :: Python :: 3.9
Classifier: Programming Language :: Python :: 3.10
Classifier: Programming Language :: Python :: 3.11
Classifier: Programming Language :: Python :: 3.12
Classifier: License :: OSI Approved :: MIT License
Classifier: Operating System :: OS Independent
Classifier: Topic :: Software Development :: Debuggers
Description-Content-Type: text/markdown
License-File: LICENSE.txt
Requires-Dist: executing >=1.2.0
Requires-Dist: asttokens >=2.1.0
Requires-Dist: pure-eval
Provides-Extra: tests
Requires-Dist: pytest ; extra == 'tests'
Requires-Dist: typeguard ; extra == 'tests'
Requires-Dist: pygments ; extra == 'tests'
Requires-Dist: littleutils ; extra == 'tests'
Requires-Dist: cython ; extra == 'tests'
# stack_data
[](https://github.com/alexmojaki/stack_data/actions/workflows/pytest.yml) [](https://coveralls.io/github/alexmojaki/stack_data?branch=master) [](https://pypi.python.org/pypi/stack_data)
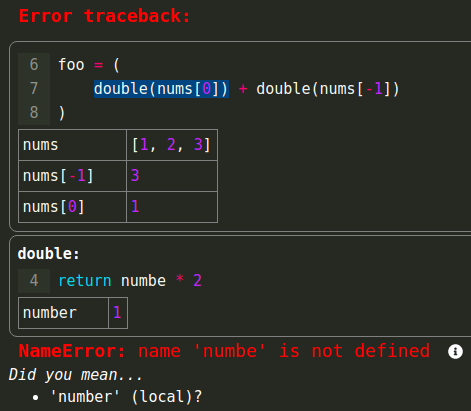
This is a library that extracts data from stack frames and tracebacks, particularly to display more useful tracebacks than the default. It powers the tracebacks in IPython and [futurecoder](https://futurecoder.io/):
You can install it from PyPI:
pip install stack_data
## Basic usage
Here's some code we'd like to inspect:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
row.append(i * j)
return result
```
Note that `foo` calls a function `print_stack()`. In reality we can imagine that an exception was raised at this line, or a debugger stopped there, but this is easy to play with directly. Here's a basic implementation:
```python
import inspect
import stack_data
def print_stack():
frame = inspect.currentframe().f_back
frame_info = stack_data.FrameInfo(frame)
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
(Beware that this has a major bug - it doesn't account for line gaps, which we'll learn about later)
The output of one call to `print_stack()` looks like:
```
foo at line 9
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(row)
--> 9 | print_stack()
10 | for j in range(5):
```
The code for `print_stack()` is fairly self-explanatory. If you want to learn more details about a particular class or method I suggest looking through some docstrings. `FrameInfo` is a class that accepts either a frame or a traceback object and provides a bunch of nice attributes and properties (which are cached so you don't need to worry about performance). In particular `frame_info.lines` is a list of `Line` objects. `line.render()` returns the source code of that line suitable for display. Without any arguments it simply strips any common leading indentation. Later on we'll see a more powerful use for it.
You can see that `frame_info.lines` includes some lines of surrounding context. By default it includes 3 pieces of context before the main line and 1 piece after. We can configure the amount of context by passing options:
```python
options = stack_data.Options(before=1, after=0)
frame_info = stack_data.FrameInfo(frame, options)
```
Then the output looks like:
```
foo at line 9
-----------
8 | result.append(row)
--> 9 | print_stack()
```
Note that these parameters are not the number of *lines* before and after to include, but the number of *pieces*. A piece is a range of one or more lines in a file that should logically be grouped together. A piece contains either a single simple statement or a part of a compound statement (loops, if, try/except, etc) that doesn't contain any other statements. Most pieces are a single line, but a multi-line statement or `if` condition is a single piece. In the example above, all pieces are one line, because nothing is spread across multiple lines. If we change our code to include some multiline bits:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(
row
)
print_stack()
for j in range(
5
):
row.append(i * j)
return result
```
and then run the original code with the default options, then the output is:
```
foo at line 11
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(
9 | row
10 | )
--> 11 | print_stack()
12 | for j in range(
13 | 5
14 | ):
```
Now lines 8-10 and lines 12-14 are each a single piece. Note that the output is essentially the same as the original in terms of the amount of code. The division of files into pieces means that the edge of the context is intuitive and doesn't crop out parts of statements or expressions. For example, if context was measured in lines instead of pieces, the last line of the above would be `for j in range(` which is much less useful.
However, if a piece is very long, including all of it could be cumbersome. For this, `Options` has a parameter `max_lines_per_piece`, which is 6 by default. Suppose we have a piece in our code that's longer than that:
```python
row = [
1,
2,
3,
4,
5,
]
```
`frame_info.lines` will truncate this piece so that instead of 7 `Line` objects it will produce 5 `Line` objects and one `LINE_GAP` in the middle, making 6 objects in total for the piece. Our code doesn't currently handle gaps, so it will raise an exception. We can modify it like so:
```python
for line in frame_info.lines:
if line is stack_data.LINE_GAP:
print(" (...)")
else:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
Now the output looks like:
```
foo at line 15
-----------
6 | for i in range(5):
7 | row = [
8 | 1,
9 | 2,
(...)
12 | 5,
13 | ]
14 | result.append(row)
--> 15 | print_stack()
16 | for j in range(5):
```
Alternatively, you can flip the condition around and check `if isinstance(line, stack_data.Line):`. Either way, you should always check for line gaps, or your code may appear to work at first but fail when it encounters a long piece.
Note that the executing piece, i.e. the piece containing the current line being executed (line 15 in this case) is never truncated, no matter how long it is.
The lines of context never stray outside `frame_info.scope`, which is the innermost function or class definition containing the current line. For example, this is the output for a short function which has neither 3 lines before nor 1 line after the current line:
```
bar at line 6
-----------
4 | def bar():
5 | foo()
--> 6 | print_stack()
```
Sometimes it's nice to ensure that the function signature is always showing. This can be done with `Options(include_signature=True)`. The result looks like this:
```
foo at line 14
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
13 | result.append(row)
--> 14 | print_stack()
15 | for j in range(5):
```
To avoid wasting space, pieces never start or end with a blank line, and blank lines between pieces are excluded. So if our code looks like this:
```python
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
```
The output doesn't change much, except you can see jumps in the line numbers:
```
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
## Variables
You can also inspect variables and other expressions in a frame, e.g:
```python
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
```
which may output:
```python
result = [[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]
i = 4
row = []
j = 4
```
`frame_info.variables` returns a list of `Variable` objects, which have attributes `name`, `value`, and `nodes`, which is a list of all AST representing that expression.
A `Variable` may refer to an expression other than a simple variable name. It can be any expression evaluated by the library [`pure_eval`](https://github.com/alexmojaki/pure_eval) which it deems 'interesting' (see those docs for more info). This includes expressions like `foo.bar` or `foo[bar]`. In these cases `name` is the source code of that expression. `pure_eval` ensures that it only evaluates expressions that won't have any side effects, e.g. where `foo.bar` is a normal attribute rather than a descriptor such as a property.
`frame_info.variables` is a list of all the interesting expressions found in `frame_info.scope`, e.g. the current function, which may include expressions not visible in `frame_info.lines`. You can restrict the list by using `frame_info.variables_in_lines` or even `frame_info.variables_in_executing_piece`. For more control you can use `frame_info.variables_by_lineno`. See the docstrings for more information.
## Rendering lines with ranges and markers
Sometimes you may want to insert special characters into the text for display purposes, e.g. HTML or ANSI color codes. `stack_data` provides a few tools to make this easier.
Let's say we have a `Line` object where `line.text` (the original raw source code of that line) is `"foo = bar"`, so `line.text[6:9]` is `"bar"`, and we want to emphasise that part by inserting HTML at positions 6 and 9 in the text. Here's how we can do that directly:
```python
markers = [
stack_data.MarkerInLine(position=6, is_start=True, string="<b>"),
stack_data.MarkerInLine(position=9, is_start=False, string="</b>"),
]
line.render(markers) # returns "foo = <b>bar</b>"
```
Here `is_start=True` indicates that the marker is the first of a pair. This helps `line.render()` sort and insert the markers correctly so you don't end up with malformed HTML like `foo<b>.<i></b>bar</i>` where tags overlap.
Since we're inserting HTML, we should actually use `line.render(markers, escape_html=True)` which will escape special HTML characters in the Python source (but not the markers) so for example `foo = bar < spam` would be rendered as `foo = <b>bar</b> < spam`.
Usually though you wouldn't create markers directly yourself. Instead you would start with one or more ranges and then convert them, like so:
```python
ranges = [
stack_data.RangeInLine(start=0, end=3, data="foo"),
stack_data.RangeInLine(start=6, end=9, data="bar"),
]
def convert_ranges(r):
if r.data == "bar":
return "<b>", "</b>"
# This results in `markers` being the same as in the above example.
markers = stack_data.markers_from_ranges(ranges, convert_ranges)
```
`RangeInLine` has a `data` attribute which can be any object. `markers_from_ranges` accepts a converter function to which it passes all the `RangeInLine` objects. If the converter function returns a pair of strings, it creates two markers from them. Otherwise it should return `None` to indicate that the range should be ignored, as with the first range containing `"foo"` in this example.
The reason this is useful is because there are built in tools to create these ranges for you. For example, if we change our `print_stack()` function to contain this:
```python
def convert_variable_ranges(r):
variable, _node = r.data
return f'<span data-value="{repr(variable.value)}">', '</span>'
markers = stack_data.markers_from_ranges(line.variable_ranges, convert_variable_ranges)
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render(markers, escape_html=True)}")
```
Then the output becomes:
```
foo at line 15
-----------
9 | def foo():
(...)
11 | for <span data-value="4">i</span> in range(5):
12 | <span data-value="[]">row</span> = []
14 | <span data-value="[[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]">result</span>.append(<span data-value="[]">row</span>)
--> 15 | print_stack()
17 | for <span data-value="4">j</span> in range(5):
```
`line.variable_ranges` is a list of RangeInLines for each Variable that appears at least partially in this line. The data attribute of the range is a pair `(variable, node)` where node is the particular AST node from the list `variable.nodes` that corresponds to this range.
You can also use `line.token_ranges` (e.g. if you want to do your own syntax highlighting) or `line.executing_node_ranges` if you want to highlight the currently executing node identified by the [`executing`](https://github.com/alexmojaki/executing) library. Or if you want to make your own range from an AST node, use `line.range_from_node(node, data)`. See the docstrings for more info.
### Syntax highlighting with Pygments
If you'd like pretty colored text without the work, you can let [Pygments](https://pygments.org/) do it for you. Just follow these steps:
1. `pip install pygments` separately as it's not a dependency of `stack_data`.
2. Create a pygments formatter object such as `HtmlFormatter` or `Terminal256Formatter`.
3. Pass the formatter to `Options` in the argument `pygments_formatter`.
4. Use `line.render(pygmented=True)` to get your formatted text. In this case you can't pass any markers to `render`.
If you want, you can also highlight the executing node in the frame in combination with the pygments syntax highlighting. For this you will need:
1. A pygments style - either a style class or a string that names it. See the [documentation on styles](https://pygments.org/docs/styles/) and the [styles gallery](https://blog.yjl.im/2015/08/pygments-styles-gallery.html).
2. A modification to make to the style for the executing node, which is a string such as `"bold"` or `"bg:#ffff00"` (yellow background). See the [documentation on style rules](https://pygments.org/docs/styles/#style-rules).
3. Pass these two things to `stack_data.style_with_executing_node(style, modifier)` to get a new style class.
4. Pass the new style to your formatter when you create it.
Note that this doesn't work with `TerminalFormatter` which just uses the basic ANSI colors and doesn't use the style passed to it in general.
## Getting the full stack
Currently `print_stack()` doesn't actually print the stack, it just prints one frame. Instead of `frame_info = FrameInfo(frame, options)`, let's do this:
```python
for frame_info in FrameInfo.stack_data(frame, options):
```
Now the output looks something like this:
```
<module> at line 18
-----------
14 | for j in range(5):
15 | row.append(i * j)
16 | return result
--> 18 | bar()
bar at line 5
-----------
4 | def bar():
--> 5 | foo()
foo at line 13
-----------
10 | for i in range(5):
11 | row = []
12 | result.append(row)
--> 13 | print_stack()
14 | for j in range(5):
```
However, just as `frame_info.lines` doesn't always yield `Line` objects, `FrameInfo.stack_data` doesn't always yield `FrameInfo` objects, and we must modify our code to handle that. Let's look at some different sample code:
```python
def factorial(x):
return x * factorial(x - 1)
try:
print(factorial(5))
except:
print_stack()
```
In this code we've forgotten to include a base case in our `factorial` function so it will fail with a `RecursionError` and there'll be many frames with similar information. Similar to the built in Python traceback, `stack_data` avoids showing all of these frames. Instead you will get a `RepeatedFrames` object which summarises the information. See its docstring for more details.
Here is our updated implementation:
```python
def print_stack():
for frame_info in FrameInfo.stack_data(sys.exc_info()[2]):
if isinstance(frame_info, FrameInfo):
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
print()
else:
print(f"... {frame_info.description} ...\n")
```
And the output:
```
<module> at line 9
-----------
4 | def factorial(x):
5 | return x * factorial(x - 1)
8 | try:
--> 9 | print(factorial(5))
10 | except:
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 5
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 4
... factorial at line 5 (996 times) ...
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = -993
```
In addition to handling repeated frames, we've passed a traceback object to `FrameInfo.stack_data` instead of a frame.
If you want, you can pass `collapse_repeated_frames=False` to `FrameInfo.stack_data` (not to `Options`) and it will just yield `FrameInfo` objects for the full stack.
|
