
diff options
| author | nechda <nechda@yandex-team.com> | 2024-08-29 23:50:27 +0300 |
|---|---|---|
| committer | nechda <nechda@yandex-team.com> | 2024-08-30 00:05:25 +0300 |
| commit | e10d6638f07a82edae3ea8197b9f5c0affcc07ea (patch) | |
| tree | 571c38cec05813766a1ad290c9d51ce7ace52919 /contrib/libs/protobuf/third_party | |
| parent | e79b38f2bbbf78d295d1901d2a79f898022d5224 (diff) | |
| download | ydb-e10d6638f07a82edae3ea8197b9f5c0affcc07ea.tar.gz | |
Update cpp-protobuf to 22.5
Привет!\
Этот PR переключат cpp & python библиотеки protobuf на версию 22.5
Если у вас возникли проблемы после влития этого PR:
1. Если начали падать канон тесты, то проведите их переканонизацию
2. Прочитайте <https://wiki.yandex-team.ru/users/nechda/obnovlenie-cpp-protobuf-22.5/> страничку с основными изменениями
3. Если страничка в вики не помогла, то пишите в [DEVTOOLSSUPPORT](https://st.yandex-team.ru/DEVTOOLSSUPPORT)
7fecade616c20a841b9e9af7b7998bdfc8d2807d
Diffstat (limited to 'contrib/libs/protobuf/third_party')
6 files changed, 1010 insertions, 0 deletions
diff --git a/contrib/libs/protobuf/third_party/utf8_range/CONTRIBUTING.md b/contrib/libs/protobuf/third_party/utf8_range/CONTRIBUTING.md new file mode 100644 index 0000000000..3e5b62eebf --- /dev/null +++ b/contrib/libs/protobuf/third_party/utf8_range/CONTRIBUTING.md @@ -0,0 +1,31 @@ +# How to Contribute + +This repository is currently a read-only clone of internal Google code for use +in open-source projects. We don't currently have a mechanism to upstream +changes, but if you'd like to contribute, please reach out to us to discuss your +proposed changes. + +## Contributor License Agreement + +Contributions to this project must be accompanied by a Contributor License +Agreement (CLA). You (or your employer) retain the copyright to your +contribution; this simply gives us permission to use and redistribute your +contributions as part of the project. Head over to +<https://cla.developers.google.com/> to see your current agreements on file or +to sign a new one. + +You generally only need to submit a CLA once, so if you've already submitted one +(even if it was for a different project), you probably don't need to do it +again. + +## Code Reviews + +All submissions, including submissions by project members, require review. We +use GitHub pull requests for this purpose. Consult +[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more +information on using pull requests. + +## Community Guidelines + +This project follows +[Google's Open Source Community Guidelines](https://opensource.google/conduct/). diff --git a/contrib/libs/protobuf/third_party/utf8_range/LICENSE b/contrib/libs/protobuf/third_party/utf8_range/LICENSE new file mode 100644 index 0000000000..e59f14fa55 --- /dev/null +++ b/contrib/libs/protobuf/third_party/utf8_range/LICENSE @@ -0,0 +1,22 @@ +MIT License + +Copyright (c) 2019 Yibo Cai +Copyright 2022 Google LLC + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/contrib/libs/protobuf/third_party/utf8_range/README.md b/contrib/libs/protobuf/third_party/utf8_range/README.md new file mode 100644 index 0000000000..30ff5b785b --- /dev/null +++ b/contrib/libs/protobuf/third_party/utf8_range/README.md @@ -0,0 +1,264 @@ +[](https://travis-ci.com/cyb70289/utf8) + +# Fast UTF-8 validation with Range algorithm (NEON+SSE4+AVX2) + +This is a brand new algorithm to leverage SIMD for fast UTF-8 string validation. Both **NEON**(armv8a) and **SSE4** versions are implemented. **AVX2** implementation contributed by [ioioioio](https://github.com/ioioioio). + +Four UTF-8 validation methods are compared on both x86 and Arm platforms. Benchmark result shows range base algorithm is the best solution on Arm, and achieves same performance as [Lemire's approach](https://lemire.me/blog/2018/05/16/validating-utf-8-strings-using-as-little-as-0-7-cycles-per-byte/) on x86. + +* Range based algorithm + * range-neon.c: NEON version + * range-sse.c: SSE4 version + * range-avx2.c: AVX2 version + * range2-neon.c, range2-sse.c: Process two blocks in one iteration +* [Lemire's SIMD implementation](https://github.com/lemire/fastvalidate-utf-8) + * lemire-sse.c: SSE4 version + * lemire-avx2.c: AVX2 version + * lemire-neon.c: NEON porting +* naive.c: Naive UTF-8 validation byte by byte +* lookup.c: [Lookup-table method](http://bjoern.hoehrmann.de/utf-8/decoder/dfa/) + +## About the code + +* Run "make" to build. Built and tested with gcc-7.3. +* Run "./utf8" to see all command line options. +* Benchmark + * Run "./utf8 bench" to bechmark all algorithms with [default test file](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt). + * Run "./utf8 bench size NUM" to benchmark specified string size. +* Run "./utf8 test" to test all algorithms with positive and negative test cases. +* To benchmark or test specific algorithm, run something like "./utf8 bench range". + +## Benchmark result (MB/s) + +### Method +1. Generate UTF-8 test buffer per [test file](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) or buffer size. +1. Call validation sub-routines in a loop until 1G bytes are checked. +1. Calculate speed(MB/s) of validating UTF-8 strings. + +### NEON(armv8a) +Test case | naive | lookup | lemire | range | range2 +:-------- | :---- | :----- | :----- | :---- | :----- +[UTF-demo.txt](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) | 562.25 | 412.84 | 1198.50 | 1411.72 | **1579.85** +32 bytes | 651.55 | 441.70 | 891.38 | 1003.95 | **1043.58** +33 bytes | 660.00 | 446.78 | 588.77 | 1009.31 | **1048.12** +129 bytes | 771.89 | 402.55 | 938.07 | 1283.77 | **1401.76** +1K bytes | 811.92 | 411.58 | 1188.96 | 1398.15 | **1560.23** +8K bytes | 812.25 | 412.74 | 1198.90 | 1412.18 | **1580.65** +64K bytes | 817.35 | 412.24 | 1200.20 | 1415.11 | **1583.86** +1M bytes | 815.70 | 411.93 | 1200.93 | 1415.65 | **1585.40** + +### SSE4(E5-2650) +Test case | naive | lookup | lemire | range | range2 +:-------- | :---- | :----- | :----- | :---- | :----- +[UTF-demo.txt](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) | 753.70 | 310.41 | 3954.74 | 3945.60 | **3986.13** +32 bytes | 1135.76 | 364.07 | **2890.52** | 2351.81 | 2173.02 +33 bytes | 1161.85 | 376.29 | 1352.95 | **2239.55** | 2041.43 +129 bytes | 1161.22 | 322.47 | 2742.49 | **3315.33** | 3249.35 +1K bytes | 1310.95 | 310.72 | 3755.88 | 3781.23 | **3874.17** +8K bytes | 1348.32 | 307.93 | 3860.71 | 3922.81 | **3968.93** +64K bytes | 1301.34 | 308.39 | 3935.15 | 3973.50 | **3983.44** +1M bytes | 1279.78 | 309.06 | 3923.51 | 3953.00 | **3960.49** + +## Range algorithm analysis + +Basic idea: +* Load 16 bytes +* Leverage SIMD to calculate value range for each byte efficiently +* Validate 16 bytes at once + +### UTF-8 coding format + +http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf, page 94 + +Table 3-7. Well-Formed UTF-8 Byte Sequences + +Code Points | First Byte | Second Byte | Third Byte | Fourth Byte | +:---------- | :--------- | :---------- | :--------- | :---------- | +U+0000..U+007F | 00..7F | | | | +U+0080..U+07FF | C2..DF | 80..BF | | | +U+0800..U+0FFF | E0 | ***A0***..BF| 80..BF | | +U+1000..U+CFFF | E1..EC | 80..BF | 80..BF | | +U+D000..U+D7FF | ED | 80..***9F***| 80..BF | | +U+E000..U+FFFF | EE..EF | 80..BF | 80..BF | | +U+10000..U+3FFFF | F0 | ***90***..BF| 80..BF | 80..BF | +U+40000..U+FFFFF | F1..F3 | 80..BF | 80..BF | 80..BF | +U+100000..U+10FFFF | F4 | 80..***8F***| 80..BF | 80..BF | + +To summarise UTF-8 encoding: +* Depending on First Byte, one legal character can be 1, 2, 3, 4 bytes + * For First Byte within C0..DF, character length = 2 + * For First Byte within E0..EF, character length = 3 + * For First Byte within F0..F4, character length = 4 +* C0, C1, F5..FF are not allowed +* Second,Third,Fourth Bytes must lie in 80..BF. +* There are four **special cases** for Second Byte, shown ***bold italic*** in above table. + +### Range table + +Range table maps range index 0 ~ 15 to minimal and maximum values allowed. Our task is to observe input string, find the pattern and set correct range index for each byte, then validate input string. + +Index | Min | Max | Byte type +:---- | :-- | :-- | :-------- +0 | 00 | 7F | First Byte, ASCII +1,2,3 | 80 | BF | Second, Third, Fourth Bytes +4 | A0 | BF | Second Byte after E0 +5 | 80 | 9F | Second Byte after ED +6 | 90 | BF | Second Byte after F0 +7 | 80 | 8F | Second Byte after F4 +8 | C2 | F4 | First Byte, non-ASCII +9..15(NEON) | FF | 00 | Illegal: unsigned char >= 255 && unsigned char <= 0 +9..15(SSE) | 7F | 80 | Illegal: signed char >= 127 && signed char <= -128 + +### Calculate byte ranges (ignore special cases) + +Ignoring the four special cases(E0,ED,F0,F4), how should we set range index for each byte? + +* Set range index to 0(00..7F) for all bytes by default +* Find non-ASCII First Byte (C0..FF), set their range index to 8(C2..F4) +* For First Byte within C0..DF, set next byte's range index to 1(80..BF) +* For First Byte within E0..EF, set next two byte's range index to 2,1(80..BF) in sequence +* For First Byte within F0..FF, set next three byte's range index to 3,2,1(80..BF) in sequence + +To implement above operations efficiently with SIMD: +* For 16 input bytes, use lookup table to map C0..DF to 1, E0..EF to 2, F0..FF to 3, others to 0. Save to first_len. +* Map C0..FF to 8, we get range indices for First Byte. +* Shift first_len one byte, we get range indices for Second Byte. +* Saturate substract first_len by one(3->2, 2->1, 1->0, 0->0), then shift two bytes, we get range indices for Third Byte. +* Saturate substract first_len by two(3->1, 2->0, 1->0, 0->0), then shift three bytes, we get range indices for Fourth Byte. + +Example(assume no previous data) + +Input | F1 | 80 | 80 | 80 | 80 | C2 | 80 | 80 | ... +:---- | :- | :- | :- | :- | :- | :- | :- | :- | :-- +*first_len* |*3* |*0* |*0* |*0* |*0* |*1* |*0* |*0* |*...* +First Byte | 8 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | ... +Second Byte | 0 | 3 | 0 | 0 | 0 | 0 | 1 | 0 | ... +Third Byte | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | ... +Fourth Byte | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... +Range index | 8 | 3 | 2 | 1 | 0 | 8 | 1 | 0 | ... + +```c +Range_index = First_Byte | Second_Byte | Third_Byte | Fourth_Byte +``` + +#### Error handling + +* C0,C1,F5..FF are not included in range table and will always be detected. +* Illegal 80..BF will have range index 0(00..7F) and be detected. +* Based on First Byte, according Second, Third and Fourth Bytes will have range index 1/2/3, to make sure they must lie in 80..BF. +* If non-ASCII First Byte overlaps, above algorithm will set range index of the latter First Byte to 9,10,11, which are illegal ranges. E.g, Input = F1 80 C2 90 --> Range index = 8 3 10 1, where 10 indicates error. See table below. + +Overlapped non-ASCII First Byte + +Input | F1 | 80 | C2 | 90 +:---- | :- | :- | :- | :- +*first_len* |*3* |*0* |*1* |*0* +First Byte | 8 | 0 | 8 | 0 +Second Byte | 0 | 3 | 0 | 1 +Third Byte | 0 | 0 | 2 | 0 +Fourth Byte | 0 | 0 | 0 | 1 +Range index | 8 | 3 |***10***| 1 + +### Adjust Second Byte range for special cases + +Range index adjustment for four special cases + +First Byte | Second Byte | Before adjustment | Correct index | Adjustment | +:--------- | :---------- | :---------------- | :------------ | :--------- +E0 | A0..BF | 2 | 4 | **2** +ED | 80..9F | 2 | 5 | **3** +F0 | 90..BF | 3 | 6 | **3** +F4 | 80..8F | 3 | 7 | **4** + +Range index adjustment can be reduced to below problem: + +***Given 16 bytes, replace E0 with 2, ED with 3, F0 with 3, F4 with 4, others with 0.*** + +A naive SIMD approach: +1. Compare 16 bytes with E0, get the mask for eacy byte (FF if equal, 00 otherwise) +1. And the mask with 2 to get adjustment for E0 +1. Repeat step 1,2 for ED,F0,F4 + +At least **eight** operations are required for naive approach. + +Observing special bytes(E0,ED,F0,F4) are close to each other, we can do much better using lookup table. + +#### NEON + +NEON ```tbl``` instruction is very convenient for table lookup: +* Table can be up to 16x4 bytes in size +* Return zero if index is out of range + +Leverage these features, we can solve the problem with as few as **two** operations: +* Precreate a 16x2 lookup table, where table[0]=2, table[13]=3, table[16]=3, table[20]=4, table[others]=0. +* Substract input bytes with E0 (E0 -> 0, ED -> 13, F0 -> 16, F4 -> 20). +* Use the substracted byte as index of lookup table and get range adjustment directly. + * For indices less than 32, we get zero or required adjustment value per input byte + * For out of bound indices, we get zero per ```tbl``` behaviour + +#### SSE + +SSE ```pshufb``` instruction is not as friendly as NEON ```tbl``` in this case: +* Table can only be 16 bytes in size +* Out of bound indices are handled this way: + * If 7-th bit of index is 0, least four bits are used as index (E.g, index 0x73 returns 3rd element) + * If 7-th bit of index is 1, return 0 (E.g, index 0x83 returns 0) + +We can still leverage these features to solve the problem in **five** operations: +* Precreate two tables: + * table_df[1] = 2, table_df[14] = 3, table_df[others] = 0 + * table_ef[1] = 3, table_ef[5] = 4, table_ef[others] = 0 +* Substract input bytes with EF (E0 -> 241, ED -> 254, F0 -> 1, F4 -> 5) to get the temporary indices +* Get range index for E0,ED + * Saturate substract temporary indices with 240 (E0 -> 1, ED -> 14, all values below 240 becomes 0) + * Use substracted indices to look up table_df, get the correct adjustment +* Get range index for F0,F4 + * Saturate add temporary indices with 112(0x70) (F0 -> 0x71, F4 -> 0x75, all values above 16 will be larger than 128(7-th bit set)) + * Use added indices to look up table_ef, get the correct adjustment (index 0x71,0x75 returns 1st,5th elements, per ```pshufb``` behaviour) + +#### Error handling + +* For overlapped non-ASCII First Byte, range index before adjustment is 9,10,11. After adjustment (adds 2,3,4 or 0), the range index will be 9 to 15, which is still illegal in range table. So the error will be detected. + +### Handling remaining bytes + +For remaining input less than 16 bytes, we will fallback to naive byte by byte approach to validate them, which is actually faster than SIMD processing. +* Look back last 16 bytes buffer to find First Byte. At most three bytes need to look back. Otherwise we either happen to be at character boundray, or there are some errors we already detected. +* Validate string byte by byte starting from the First Byte. + +## Tests + +It's necessary to design test cases to cover corner cases as more as possible. + +### Positive cases + +1. Prepare correct characters +2. Validate correct characters +3. Validate long strings + * Round concatenate characters starting from first character to 1024 bytes + * Validate 1024 bytes string + * Shift 1 byte, validate 1025 bytes string + * Shift 2 bytes, Validate 1026 bytes string + * ... + * Shift 16 bytes, validate 1040 bytes string +4. Repeat step3, test buffer starting from second character +5. Repeat step3, test buffer starting from third character +6. ... + +### Negative cases + +1. Prepare bad characters and bad strings + * Bad character + * Bad character cross 16 bytes boundary + * Bad character cross last 16 bytes and remaining bytes boundary +2. Test long strings + * Prepare correct long strings same as positive cases + * Append bad characters + * Shift one byte for each iteration + * Validate each shift + +## Code breakdown + +Below table shows how 16 bytes input are processed step by step. See [range-neon.c](range-neon.c) for according code. + +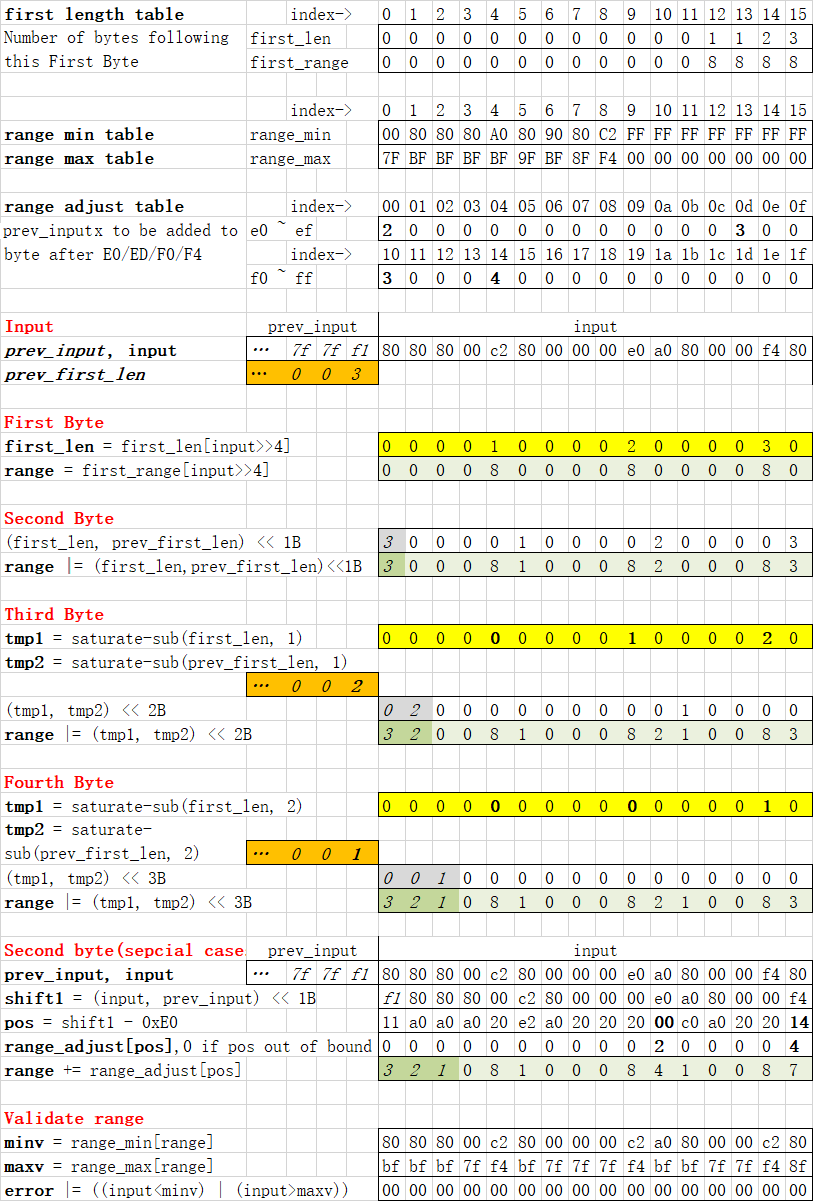 diff --git a/contrib/libs/protobuf/third_party/utf8_range/UTF-8-demo.txt b/contrib/libs/protobuf/third_party/utf8_range/UTF-8-demo.txt new file mode 100644 index 0000000000..ff915b268a --- /dev/null +++ b/contrib/libs/protobuf/third_party/utf8_range/UTF-8-demo.txt @@ -0,0 +1,212 @@ + +UTF-8 encoded sample plain-text file +‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾ + +Markus Kuhn [ˈmaʳkʊs kuːn] <http://www.cl.cam.ac.uk/~mgk25/> — 2002-07-25 CC BY + + +The ASCII compatible UTF-8 encoding used in this plain-text file +is defined in Unicode, ISO 10646-1, and RFC 2279. + + +Using Unicode/UTF-8, you can write in emails and source code things such as + +Mathematics and sciences: + + ∮ E⋅da = Q, n → ∞, ∑ f(i) = ∏ g(i), ⎧⎡⎛┌─────┐⎞⎤⎫ + ⎪⎢⎜│a²+b³ ⎟⎥⎪ + ∀x∈ℝ: ⌈x⌉ = −⌊−x⌋, α ∧ ¬β = ¬(¬α ∨ β), ⎪⎢⎜│───── ⎟⎥⎪ + ⎪⎢⎜⎷ c₈ ⎟⎥⎪ + ℕ ⊆ ℕ₀ ⊂ ℤ ⊂ ℚ ⊂ ℝ ⊂ ℂ, ⎨⎢⎜ ⎟⎥⎬ + ⎪⎢⎜ ∞ ⎟⎥⎪ + ⊥ < a ≠ b ≡ c ≤ d ≪ ⊤ ⇒ (⟦A⟧ ⇔ ⟪B⟫), ⎪⎢⎜ ⎲ ⎟⎥⎪ + ⎪⎢⎜ ⎳aⁱ-bⁱ⎟⎥⎪ + 2H₂ + O₂ ⇌ 2H₂O, R = 4.7 kΩ, ⌀ 200 mm ⎩⎣⎝i=1 ⎠⎦⎭ + +Linguistics and dictionaries: + + ði ıntəˈnæʃənəl fəˈnɛtık əsoʊsiˈeıʃn + Y [ˈʏpsilɔn], Yen [jɛn], Yoga [ˈjoːgɑ] + +APL: + + ((V⍳V)=⍳⍴V)/V←,V ⌷←⍳→⍴∆∇⊃‾⍎⍕⌈ + +Nicer typography in plain text files: + + ╔══════════════════════════════════════════╗ + ║ ║ + ║ • ‘single’ and “double” quotes ║ + ║ ║ + ║ • Curly apostrophes: “We’ve been here” ║ + ║ ║ + ║ • Latin-1 apostrophe and accents: '´` ║ + ║ ║ + ║ • ‚deutsche‘ „Anführungszeichen“ ║ + ║ ║ + ║ • †, ‡, ‰, •, 3–4, —, −5/+5, ™, … ║ + ║ ║ + ║ • ASCII safety test: 1lI|, 0OD, 8B ║ + ║ ╭─────────╮ ║ + ║ • the euro symbol: │ 14.95 € │ ║ + ║ ╰─────────╯ ║ + ╚══════════════════════════════════════════╝ + +Combining characters: + + STARGΛ̊TE SG-1, a = v̇ = r̈, a⃑ ⊥ b⃑ + +Greek (in Polytonic): + + The Greek anthem: + + Σὲ γνωρίζω ἀπὸ τὴν κόψη + τοῦ σπαθιοῦ τὴν τρομερή, + σὲ γνωρίζω ἀπὸ τὴν ὄψη + ποὺ μὲ βία μετράει τὴ γῆ. + + ᾿Απ᾿ τὰ κόκκαλα βγαλμένη + τῶν ῾Ελλήνων τὰ ἱερά + καὶ σὰν πρῶτα ἀνδρειωμένη + χαῖρε, ὦ χαῖρε, ᾿Ελευθεριά! + + From a speech of Demosthenes in the 4th century BC: + + Οὐχὶ ταὐτὰ παρίσταταί μοι γιγνώσκειν, ὦ ἄνδρες ᾿Αθηναῖοι, + ὅταν τ᾿ εἰς τὰ πράγματα ἀποβλέψω καὶ ὅταν πρὸς τοὺς + λόγους οὓς ἀκούω· τοὺς μὲν γὰρ λόγους περὶ τοῦ + τιμωρήσασθαι Φίλιππον ὁρῶ γιγνομένους, τὰ δὲ πράγματ᾿ + εἰς τοῦτο προήκοντα, ὥσθ᾿ ὅπως μὴ πεισόμεθ᾿ αὐτοὶ + πρότερον κακῶς σκέψασθαι δέον. οὐδέν οὖν ἄλλο μοι δοκοῦσιν + οἱ τὰ τοιαῦτα λέγοντες ἢ τὴν ὑπόθεσιν, περὶ ἧς βουλεύεσθαι, + οὐχὶ τὴν οὖσαν παριστάντες ὑμῖν ἁμαρτάνειν. ἐγὼ δέ, ὅτι μέν + ποτ᾿ ἐξῆν τῇ πόλει καὶ τὰ αὑτῆς ἔχειν ἀσφαλῶς καὶ Φίλιππον + τιμωρήσασθαι, καὶ μάλ᾿ ἀκριβῶς οἶδα· ἐπ᾿ ἐμοῦ γάρ, οὐ πάλαι + γέγονεν ταῦτ᾿ ἀμφότερα· νῦν μέντοι πέπεισμαι τοῦθ᾿ ἱκανὸν + προλαβεῖν ἡμῖν εἶναι τὴν πρώτην, ὅπως τοὺς συμμάχους + σώσομεν. ἐὰν γὰρ τοῦτο βεβαίως ὑπάρξῃ, τότε καὶ περὶ τοῦ + τίνα τιμωρήσεταί τις καὶ ὃν τρόπον ἐξέσται σκοπεῖν· πρὶν δὲ + τὴν ἀρχὴν ὀρθῶς ὑποθέσθαι, μάταιον ἡγοῦμαι περὶ τῆς + τελευτῆς ὁντινοῦν ποιεῖσθαι λόγον. + + Δημοσθένους, Γ´ ᾿Ολυνθιακὸς + +Georgian: + + From a Unicode conference invitation: + + გთხოვთ ახლავე გაიაროთ რეგისტრაცია Unicode-ის მეათე საერთაშორისო + კონფერენციაზე დასასწრებად, რომელიც გაიმართება 10-12 მარტს, + ქ. მაინცში, გერმანიაში. კონფერენცია შეჰკრებს ერთად მსოფლიოს + ექსპერტებს ისეთ დარგებში როგორიცაა ინტერნეტი და Unicode-ი, + ინტერნაციონალიზაცია და ლოკალიზაცია, Unicode-ის გამოყენება + ოპერაციულ სისტემებსა, და გამოყენებით პროგრამებში, შრიფტებში, + ტექსტების დამუშავებასა და მრავალენოვან კომპიუტერულ სისტემებში. + +Russian: + + From a Unicode conference invitation: + + Зарегистрируйтесь сейчас на Десятую Международную Конференцию по + Unicode, которая состоится 10-12 марта 1997 года в Майнце в Германии. + Конференция соберет широкий круг экспертов по вопросам глобального + Интернета и Unicode, локализации и интернационализации, воплощению и + применению Unicode в различных операционных системах и программных + приложениях, шрифтах, верстке и многоязычных компьютерных системах. + +Thai (UCS Level 2): + + Excerpt from a poetry on The Romance of The Three Kingdoms (a Chinese + classic 'San Gua'): + + [----------------------------|------------------------] + ๏ แผ่นดินฮั่นเสื่อมโทรมแสนสังเวช พระปกเกศกองบู๊กู้ขึ้นใหม่ + สิบสองกษัตริย์ก่อนหน้าแลถัดไป สององค์ไซร้โง่เขลาเบาปัญญา + ทรงนับถือขันทีเป็นที่พึ่ง บ้านเมืองจึงวิปริตเป็นนักหนา + โฮจิ๋นเรียกทัพทั่วหัวเมืองมา หมายจะฆ่ามดชั่วตัวสำคัญ + เหมือนขับไสไล่เสือจากเคหา รับหมาป่าเข้ามาเลยอาสัญ + ฝ่ายอ้องอุ้นยุแยกให้แตกกัน ใช้สาวนั้นเป็นชนวนชื่นชวนใจ + พลันลิฉุยกุยกีกลับก่อเหตุ ช่างอาเพศจริงหนาฟ้าร้องไห้ + ต้องรบราฆ่าฟันจนบรรลัย ฤๅหาใครค้ำชูกู้บรรลังก์ ฯ + + (The above is a two-column text. If combining characters are handled + correctly, the lines of the second column should be aligned with the + | character above.) + +Ethiopian: + + Proverbs in the Amharic language: + + ሰማይ አይታረስ ንጉሥ አይከሰስ። + ብላ ካለኝ እንደአባቴ በቆመጠኝ። + ጌጥ ያለቤቱ ቁምጥና ነው። + ደሀ በሕልሙ ቅቤ ባይጠጣ ንጣት በገደለው። + የአፍ ወለምታ በቅቤ አይታሽም። + አይጥ በበላ ዳዋ ተመታ። + ሲተረጉሙ ይደረግሙ። + ቀስ በቀስ፥ ዕንቁላል በእግሩ ይሄዳል። + ድር ቢያብር አንበሳ ያስር። + ሰው እንደቤቱ እንጅ እንደ ጉረቤቱ አይተዳደርም። + እግዜር የከፈተውን ጉሮሮ ሳይዘጋው አይድርም። + የጎረቤት ሌባ፥ ቢያዩት ይስቅ ባያዩት ያጠልቅ። + ሥራ ከመፍታት ልጄን ላፋታት። + ዓባይ ማደሪያ የለው፥ ግንድ ይዞ ይዞራል። + የእስላም አገሩ መካ የአሞራ አገሩ ዋርካ። + ተንጋሎ ቢተፉ ተመልሶ ባፉ። + ወዳጅህ ማር ቢሆን ጨርስህ አትላሰው። + እግርህን በፍራሽህ ልክ ዘርጋ። + +Runes: + + ᚻᛖ ᚳᚹᚫᚦ ᚦᚫᛏ ᚻᛖ ᛒᚢᛞᛖ ᚩᚾ ᚦᚫᛗ ᛚᚪᚾᛞᛖ ᚾᚩᚱᚦᚹᛖᚪᚱᛞᚢᛗ ᚹᛁᚦ ᚦᚪ ᚹᛖᛥᚫ + + (Old English, which transcribed into Latin reads 'He cwaeth that he + bude thaem lande northweardum with tha Westsae.' and means 'He said + that he lived in the northern land near the Western Sea.') + +Braille: + + ⡌⠁⠧⠑ ⠼⠁⠒ ⡍⠜⠇⠑⠹⠰⠎ ⡣⠕⠌ + + ⡍⠜⠇⠑⠹ ⠺⠁⠎ ⠙⠑⠁⠙⠒ ⠞⠕ ⠃⠑⠛⠔ ⠺⠊⠹⠲ ⡹⠻⠑ ⠊⠎ ⠝⠕ ⠙⠳⠃⠞ + ⠱⠁⠞⠑⠧⠻ ⠁⠃⠳⠞ ⠹⠁⠞⠲ ⡹⠑ ⠗⠑⠛⠊⠌⠻ ⠕⠋ ⠙⠊⠎ ⠃⠥⠗⠊⠁⠇ ⠺⠁⠎ + ⠎⠊⠛⠝⠫ ⠃⠹ ⠹⠑ ⠊⠇⠻⠛⠹⠍⠁⠝⠂ ⠹⠑ ⠊⠇⠻⠅⠂ ⠹⠑ ⠥⠝⠙⠻⠞⠁⠅⠻⠂ + ⠁⠝⠙ ⠹⠑ ⠡⠊⠑⠋ ⠍⠳⠗⠝⠻⠲ ⡎⠊⠗⠕⠕⠛⠑ ⠎⠊⠛⠝⠫ ⠊⠞⠲ ⡁⠝⠙ + ⡎⠊⠗⠕⠕⠛⠑⠰⠎ ⠝⠁⠍⠑ ⠺⠁⠎ ⠛⠕⠕⠙ ⠥⠏⠕⠝ ⠰⡡⠁⠝⠛⠑⠂ ⠋⠕⠗ ⠁⠝⠹⠹⠔⠛ ⠙⠑ + ⠡⠕⠎⠑ ⠞⠕ ⠏⠥⠞ ⠙⠊⠎ ⠙⠁⠝⠙ ⠞⠕⠲ + + ⡕⠇⠙ ⡍⠜⠇⠑⠹ ⠺⠁⠎ ⠁⠎ ⠙⠑⠁⠙ ⠁⠎ ⠁ ⠙⠕⠕⠗⠤⠝⠁⠊⠇⠲ + + ⡍⠔⠙⠖ ⡊ ⠙⠕⠝⠰⠞ ⠍⠑⠁⠝ ⠞⠕ ⠎⠁⠹ ⠹⠁⠞ ⡊ ⠅⠝⠪⠂ ⠕⠋ ⠍⠹ + ⠪⠝ ⠅⠝⠪⠇⠫⠛⠑⠂ ⠱⠁⠞ ⠹⠻⠑ ⠊⠎ ⠏⠜⠞⠊⠊⠥⠇⠜⠇⠹ ⠙⠑⠁⠙ ⠁⠃⠳⠞ + ⠁ ⠙⠕⠕⠗⠤⠝⠁⠊⠇⠲ ⡊ ⠍⠊⠣⠞ ⠙⠁⠧⠑ ⠃⠑⠲ ⠔⠊⠇⠔⠫⠂ ⠍⠹⠎⠑⠇⠋⠂ ⠞⠕ + ⠗⠑⠛⠜⠙ ⠁ ⠊⠕⠋⠋⠔⠤⠝⠁⠊⠇ ⠁⠎ ⠹⠑ ⠙⠑⠁⠙⠑⠌ ⠏⠊⠑⠊⠑ ⠕⠋ ⠊⠗⠕⠝⠍⠕⠝⠛⠻⠹ + ⠔ ⠹⠑ ⠞⠗⠁⠙⠑⠲ ⡃⠥⠞ ⠹⠑ ⠺⠊⠎⠙⠕⠍ ⠕⠋ ⠳⠗ ⠁⠝⠊⠑⠌⠕⠗⠎ + ⠊⠎ ⠔ ⠹⠑ ⠎⠊⠍⠊⠇⠑⠆ ⠁⠝⠙ ⠍⠹ ⠥⠝⠙⠁⠇⠇⠪⠫ ⠙⠁⠝⠙⠎ + ⠩⠁⠇⠇ ⠝⠕⠞ ⠙⠊⠌⠥⠗⠃ ⠊⠞⠂ ⠕⠗ ⠹⠑ ⡊⠳⠝⠞⠗⠹⠰⠎ ⠙⠕⠝⠑ ⠋⠕⠗⠲ ⡹⠳ + ⠺⠊⠇⠇ ⠹⠻⠑⠋⠕⠗⠑ ⠏⠻⠍⠊⠞ ⠍⠑ ⠞⠕ ⠗⠑⠏⠑⠁⠞⠂ ⠑⠍⠏⠙⠁⠞⠊⠊⠁⠇⠇⠹⠂ ⠹⠁⠞ + ⡍⠜⠇⠑⠹ ⠺⠁⠎ ⠁⠎ ⠙⠑⠁⠙ ⠁⠎ ⠁ ⠙⠕⠕⠗⠤⠝⠁⠊⠇⠲ + + (The first couple of paragraphs of "A Christmas Carol" by Dickens) + +Compact font selection example text: + + ABCDEFGHIJKLMNOPQRSTUVWXYZ /0123456789 + abcdefghijklmnopqrstuvwxyz £©µÀÆÖÞßéöÿ + –—‘“”„†•…‰™œŠŸž€ ΑΒΓΔΩαβγδω АБВГДабвгд + ∀∂∈ℝ∧∪≡∞ ↑↗↨↻⇣ ┐┼╔╘░►☺♀ fi�⑀₂ἠḂӥẄɐː⍎אԱა + +Greetings in various languages: + + Hello world, Καλημέρα κόσμε, コンニチハ + +Box drawing alignment tests: █ + ▉ + ╔══╦══╗ ┌──┬──┐ ╭──┬──╮ ╭──┬──╮ ┏━━┳━━┓ ┎┒┏┑ ╷ ╻ ┏┯┓ ┌┰┐ ▊ ╱╲╱╲╳╳╳ + ║┌─╨─┐║ │╔═╧═╗│ │╒═╪═╕│ │╓─╁─╖│ ┃┌─╂─┐┃ ┗╃╄┙ ╶┼╴╺╋╸┠┼┨ ┝╋┥ ▋ ╲╱╲╱╳╳╳ + ║│╲ ╱│║ │║ ║│ ││ │ ││ │║ ┃ ║│ ┃│ ╿ │┃ ┍╅╆┓ ╵ ╹ ┗┷┛ └┸┘ ▌ ╱╲╱╲╳╳╳ + ╠╡ ╳ ╞╣ ├╢ ╟┤ ├┼─┼─┼┤ ├╫─╂─╫┤ ┣┿╾┼╼┿┫ ┕┛┖┚ ┌┄┄┐ ╎ ┏┅┅┓ ┋ ▍ ╲╱╲╱╳╳╳ + ║│╱ ╲│║ │║ ║│ ││ │ ││ │║ ┃ ║│ ┃│ ╽ │┃ ░░▒▒▓▓██ ┊ ┆ ╎ ╏ ┇ ┋ ▎ + ║└─╥─┘║ │╚═╤═╝│ │╘═╪═╛│ │╙─╀─╜│ ┃└─╂─┘┃ ░░▒▒▓▓██ ┊ ┆ ╎ ╏ ┇ ┋ ▏ + ╚══╩══╝ └──┴──┘ ╰──┴──╯ ╰──┴──╯ ┗━━┻━━┛ ▗▄▖▛▀▜ └╌╌┘ ╎ ┗╍╍┛ ┋ ▁▂▃▄▅▆▇█ + ▝▀▘▙▄▟ diff --git a/contrib/libs/protobuf/third_party/utf8_range/utf8_validity.cc b/contrib/libs/protobuf/third_party/utf8_range/utf8_validity.cc new file mode 100644 index 0000000000..c77c99636a --- /dev/null +++ b/contrib/libs/protobuf/third_party/utf8_range/utf8_validity.cc @@ -0,0 +1,458 @@ +// Copyright 2022 Google LLC +// +// Use of this source code is governed by an MIT-style +// license that can be found in the LICENSE file or at +// https://opensource.org/licenses/MIT. + +/* This is a wrapper for the Google range-sse.cc algorithm which checks whether a + * sequence of bytes is a valid UTF-8 sequence and finds the longest valid prefix of + * the UTF-8 sequence. + * + * The key difference is that it checks for as much ASCII symbols as possible + * and then falls back to the range-sse.cc algorithm. The changes to the + * algorithm are cosmetic, mostly to trick the clang compiler to produce optimal + * code. + * + * For API see the utf8_validity.h header. + */ +#include "utf8_validity.h" + +#include <cstddef> +#include <cstdint> + +#include "y_absl/strings/ascii.h" +#include "y_absl/strings/string_view.h" + +#ifdef __SSE4_1__ +#include <emmintrin.h> +#include <smmintrin.h> +#include <tmmintrin.h> +#endif + +namespace utf8_range { +namespace { + +inline arc_ui64 UNALIGNED_LOAD64(const void* p) { + arc_ui64 t; + memcpy(&t, p, sizeof t); + return t; +} + +inline bool TrailByteOk(const char c) { + return static_cast<int8_t>(c) <= static_cast<int8_t>(0xBF); +} + +/* If ReturnPosition is false then it returns 1 if |data| is a valid utf8 + * sequence, otherwise returns 0. + * If ReturnPosition is set to true, returns the length in bytes of the prefix + of |data| that is all structurally valid UTF-8. + */ +template <bool ReturnPosition> +size_t ValidUTF8Span(const char* data, const char* end) { + /* We return err_pos in the loop which is always 0 if !ReturnPosition */ + size_t err_pos = 0; + size_t codepoint_bytes = 0; + /* The early check is done because of early continue's on codepoints of all + * sizes, i.e. we first check for ascii and if it is, we call continue, then + * for 2 byte codepoints, etc. This is done in order to reduce indentation and + * improve readability of the codepoint validity check. + */ + while (data + codepoint_bytes < end) { + if (ReturnPosition) { + err_pos += codepoint_bytes; + } + data += codepoint_bytes; + const size_t len = end - data; + const unsigned char byte1 = data[0]; + + /* We do not skip many ascii bytes at the same time as this function is + used for tail checking (< 16 bytes) and for non x86 platforms. We also + don't think that cases where non-ASCII codepoints are followed by ascii + happen often. For small strings it also introduces some penalty. For + purely ascii UTF8 strings (which is the overwhelming case) we call + SkipAscii function which is multiplatform and extremely fast. + */ + /* [00..7F] ASCII -> 1 byte */ + if (y_absl::ascii_isascii(byte1)) { + codepoint_bytes = 1; + continue; + } + /* [C2..DF], [80..BF] -> 2 bytes */ + if (len >= 2 && byte1 >= 0xC2 && byte1 <= 0xDF && TrailByteOk(data[1])) { + codepoint_bytes = 2; + continue; + } + if (len >= 3) { + const unsigned char byte2 = data[1]; + const unsigned char byte3 = data[2]; + + /* Is byte2, byte3 between [0x80, 0xBF] + * Check for 0x80 was done above. + */ + if (!TrailByteOk(byte2) || !TrailByteOk(byte3)) { + return err_pos; + } + + if (/* E0, A0..BF, 80..BF */ + ((byte1 == 0xE0 && byte2 >= 0xA0) || + /* E1..EC, 80..BF, 80..BF */ + (byte1 >= 0xE1 && byte1 <= 0xEC) || + /* ED, 80..9F, 80..BF */ + (byte1 == 0xED && byte2 <= 0x9F) || + /* EE..EF, 80..BF, 80..BF */ + (byte1 >= 0xEE && byte1 <= 0xEF))) { + codepoint_bytes = 3; + continue; + } + if (len >= 4) { + const unsigned char byte4 = data[3]; + /* Is byte4 between 0x80 ~ 0xBF */ + if (!TrailByteOk(byte4)) { + return err_pos; + } + + if (/* F0, 90..BF, 80..BF, 80..BF */ + ((byte1 == 0xF0 && byte2 >= 0x90) || + /* F1..F3, 80..BF, 80..BF, 80..BF */ + (byte1 >= 0xF1 && byte1 <= 0xF3) || + /* F4, 80..8F, 80..BF, 80..BF */ + (byte1 == 0xF4 && byte2 <= 0x8F))) { + codepoint_bytes = 4; + continue; + } + } + } + return err_pos; + } + if (ReturnPosition) { + err_pos += codepoint_bytes; + } + /* if ReturnPosition is false, this returns 1. + * if ReturnPosition is true, this returns err_pos. + */ + return err_pos + (1 - ReturnPosition); +} + +/* Returns the number of bytes needed to skip backwards to get to the first + byte of codepoint. + */ +inline int CodepointSkipBackwards(arc_i32 codepoint_word) { + const int8_t* const codepoint = + reinterpret_cast<const int8_t*>(&codepoint_word); + if (!TrailByteOk(codepoint[3])) { + return 1; + } else if (!TrailByteOk(codepoint[2])) { + return 2; + } else if (!TrailByteOk(codepoint[1])) { + return 3; + } + return 0; +} + +/* Skipping over ASCII as much as possible, per 8 bytes. It is intentional + as most strings to check for validity consist only of 1 byte codepoints. + */ +inline const char* SkipAscii(const char* data, const char* end) { + while (8 <= end - data && + (UNALIGNED_LOAD64(data) & 0x8080808080808080) == 0) { + data += 8; + } + while (data < end && y_absl::ascii_isascii(*data)) { + ++data; + } + return data; +} + +template <bool ReturnPosition> +size_t ValidUTF8(const char* data, size_t len) { + if (len == 0) return 1 - ReturnPosition; + const char* const end = data + len; + data = SkipAscii(data, end); + /* SIMD algorithm always outperforms the naive version for any data of + length >=16. + */ + if (end - data < 16) { + return (ReturnPosition ? (data - (end - len)) : 0) + + ValidUTF8Span<ReturnPosition>(data, end); + } +#ifndef __SSE4_1__ + return (ReturnPosition ? (data - (end - len)) : 0) + + ValidUTF8Span<ReturnPosition>(data, end); +#else + /* This code checks that utf-8 ranges are structurally valid 16 bytes at once + * using superscalar instructions. + * The mapping between ranges of codepoint and their corresponding utf-8 + * sequences is below. + */ + + /* + * U+0000...U+007F 00...7F + * U+0080...U+07FF C2...DF 80...BF + * U+0800...U+0FFF E0 A0...BF 80...BF + * U+1000...U+CFFF E1...EC 80...BF 80...BF + * U+D000...U+D7FF ED 80...9F 80...BF + * U+E000...U+FFFF EE...EF 80...BF 80...BF + * U+10000...U+3FFFF F0 90...BF 80...BF 80...BF + * U+40000...U+FFFFF F1...F3 80...BF 80...BF 80...BF + * U+100000...U+10FFFF F4 80...8F 80...BF 80...BF + */ + + /* First we compute the type for each byte, as given by the table below. + * This type will be used as an index later on. + */ + + /* + * Index Min Max Byte Type + * 0 00 7F Single byte sequence + * 1,2,3 80 BF Second, third and fourth byte for many of the sequences. + * 4 A0 BF Second byte after E0 + * 5 80 9F Second byte after ED + * 6 90 BF Second byte after F0 + * 7 80 8F Second byte after F4 + * 8 C2 F4 First non ASCII byte + * 9..15 7F 80 Invalid byte + */ + + /* After the first step we compute the index for all bytes, then we permute + the bytes according to their indices to check the ranges from the range + table. + * The range for a given type can be found in the range_min_table and + range_max_table, the range for type/index X is in range_min_table[X] ... + range_max_table[X]. + */ + + /* Algorithm: + * Put index zero to all bytes. + * Find all non ASCII characters, give them index 8. + * For each tail byte in a codepoint sequence, give it an index corresponding + to the 1 based index from the end. + * If the first byte of the codepoint is in the [C0...DF] range, we write + index 1 in the following byte. + * If the first byte of the codepoint is in the range [E0...EF], we write + indices 2 and 1 in the next two bytes. + * If the first byte of the codepoint is in the range [F0...FF] we write + indices 3,2,1 into the next three bytes. + * For finding the number of bytes we need to look at high nibbles (4 bits) + and do the lookup from the table, it can be done with shift by 4 + shuffle + instructions. We call it `first_len`. + * Then we shift first_len by 8 bits to get the indices of the 2nd bytes. + * Saturating sub 1 and shift by 8 bits to get the indices of the 3rd bytes. + * Again to get the indices of the 4th bytes. + * Take OR of all that 4 values and check within range. + */ + /* For example: + * input C3 80 68 E2 80 20 A6 F0 A0 80 AC 20 F0 93 80 80 + * first_len 1 0 0 2 0 0 0 3 0 0 0 0 3 0 0 0 + * 1st byte 8 0 0 8 0 0 0 8 0 0 0 0 8 0 0 0 + * 2nd byte 0 1 0 0 2 0 0 0 3 0 0 0 0 3 0 0 // Shift + sub + * 3rd byte 0 0 0 0 0 1 0 0 0 2 0 0 0 0 2 0 // Shift + sub + * 4th byte 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 // Shift + sub + * Index 8 1 0 8 2 1 0 8 3 2 1 0 8 3 2 1 // OR of results + */ + + /* Checking for errors: + * Error checking is done by looking up the high nibble (4 bits) of each byte + against an error checking table. + * Because the lookup value for the second byte depends of the value of the + first byte in codepoint, we use saturated operations to adjust the index. + * Specifically we need to add 2 for E0, 3 for ED, 3 for F0 and 4 for F4 to + match the correct index. + * If we subtract from all bytes EF then EO -> 241, ED -> 254, F0 -> 1, + F4 -> 5 + * Do saturating sub 240, then E0 -> 1, ED -> 14 and we can do lookup to + match the adjustment + * Add saturating 112, then F0 -> 113, F4 -> 117, all that were > 16 will + be more 128 and lookup in ef_fe_table will return 0 but for F0 + and F4 it will be 4 and 5 accordingly + */ + /* + * Then just check the appropriate ranges with greater/smaller equal + instructions. Check tail with a naive algorithm. + * To save from previous 16 byte checks we just align previous_first_len to + get correct continuations of the codepoints. + */ + + /* + * Map high nibble of "First Byte" to legal character length minus 1 + * 0x00 ~ 0xBF --> 0 + * 0xC0 ~ 0xDF --> 1 + * 0xE0 ~ 0xEF --> 2 + * 0xF0 ~ 0xFF --> 3 + */ + const __m128i first_len_table = + _mm_setr_epi8(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3); + + /* Map "First Byte" to 8-th item of range table (0xC2 ~ 0xF4) */ + const __m128i first_range_table = + _mm_setr_epi8(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8); + + /* + * Range table, map range index to min and max values + */ + const __m128i range_min_table = + _mm_setr_epi8(0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, 0xC2, 0x7F, + 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F); + + const __m128i range_max_table = + _mm_setr_epi8(0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, 0xF4, 0x80, + 0x80, 0x80, 0x80, 0x80, 0x80, 0x80); + + /* + * Tables for fast handling of four special First Bytes(E0,ED,F0,F4), after + * which the Second Byte are not 80~BF. It contains "range index adjustment". + * +------------+---------------+------------------+----------------+ + * | First Byte | original range| range adjustment | adjusted range | + * +------------+---------------+------------------+----------------+ + * | E0 | 2 | 2 | 4 | + * +------------+---------------+------------------+----------------+ + * | ED | 2 | 3 | 5 | + * +------------+---------------+------------------+----------------+ + * | F0 | 3 | 3 | 6 | + * +------------+---------------+------------------+----------------+ + * | F4 | 4 | 4 | 8 | + * +------------+---------------+------------------+----------------+ + */ + + /* df_ee_table[1] -> E0, df_ee_table[14] -> ED as ED - E0 = 13 */ + // The values represent the adjustment in the Range Index table for a correct + // index. + const __m128i df_ee_table = + _mm_setr_epi8(0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0); + + /* ef_fe_table[1] -> F0, ef_fe_table[5] -> F4, F4 - F0 = 4 */ + // The values represent the adjustment in the Range Index table for a correct + // index. + const __m128i ef_fe_table = + _mm_setr_epi8(0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0); + + __m128i prev_input = _mm_set1_epi8(0); + __m128i prev_first_len = _mm_set1_epi8(0); + __m128i error = _mm_set1_epi8(0); + while (end - data >= 16) { + const __m128i input = + _mm_loadu_si128(reinterpret_cast<const __m128i*>(data)); + + /* high_nibbles = input >> 4 */ + const __m128i high_nibbles = + _mm_and_si128(_mm_srli_epi16(input, 4), _mm_set1_epi8(0x0F)); + + /* first_len = legal character length minus 1 */ + /* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ + /* first_len = first_len_table[high_nibbles] */ + __m128i first_len = _mm_shuffle_epi8(first_len_table, high_nibbles); + + /* First Byte: set range index to 8 for bytes within 0xC0 ~ 0xFF */ + /* range = first_range_table[high_nibbles] */ + __m128i range = _mm_shuffle_epi8(first_range_table, high_nibbles); + + /* Second Byte: set range index to first_len */ + /* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ + /* range |= (first_len, prev_first_len) << 1 byte */ + range = _mm_or_si128(range, _mm_alignr_epi8(first_len, prev_first_len, 15)); + + /* Third Byte: set range index to saturate_sub(first_len, 1) */ + /* 0 for 00~7F, 0 for C0~DF, 1 for E0~EF, 2 for F0~FF */ + __m128i tmp1; + __m128i tmp2; + /* tmp1 = saturate_sub(first_len, 1) */ + tmp1 = _mm_subs_epu8(first_len, _mm_set1_epi8(1)); + /* tmp2 = saturate_sub(prev_first_len, 1) */ + tmp2 = _mm_subs_epu8(prev_first_len, _mm_set1_epi8(1)); + /* range |= (tmp1, tmp2) << 2 bytes */ + range = _mm_or_si128(range, _mm_alignr_epi8(tmp1, tmp2, 14)); + + /* Fourth Byte: set range index to saturate_sub(first_len, 2) */ + /* 0 for 00~7F, 0 for C0~DF, 0 for E0~EF, 1 for F0~FF */ + /* tmp1 = saturate_sub(first_len, 2) */ + tmp1 = _mm_subs_epu8(first_len, _mm_set1_epi8(2)); + /* tmp2 = saturate_sub(prev_first_len, 2) */ + tmp2 = _mm_subs_epu8(prev_first_len, _mm_set1_epi8(2)); + /* range |= (tmp1, tmp2) << 3 bytes */ + range = _mm_or_si128(range, _mm_alignr_epi8(tmp1, tmp2, 13)); + + /* + * Now we have below range indices calculated + * Correct cases: + * - 8 for C0~FF + * - 3 for 1st byte after F0~FF + * - 2 for 1st byte after E0~EF or 2nd byte after F0~FF + * - 1 for 1st byte after C0~DF or 2nd byte after E0~EF or + * 3rd byte after F0~FF + * - 0 for others + * Error cases: + * >9 for non ascii First Byte overlapping + * E.g., F1 80 C2 90 --> 8 3 10 2, where 10 indicates error + */ + + /* Adjust Second Byte range for special First Bytes(E0,ED,F0,F4) */ + /* Overlaps lead to index 9~15, which are illegal in range table */ + __m128i shift1; + __m128i pos; + __m128i range2; + /* shift1 = (input, prev_input) << 1 byte */ + shift1 = _mm_alignr_epi8(input, prev_input, 15); + pos = _mm_sub_epi8(shift1, _mm_set1_epi8(0xEF)); + /* + * shift1: | EF F0 ... FE | FF 00 ... ... DE | DF E0 ... EE | + * pos: | 0 1 15 | 16 17 239| 240 241 255| + * pos-240: | 0 0 0 | 0 0 0 | 0 1 15 | + * pos+112: | 112 113 127| >= 128 | >= 128 | + */ + tmp1 = _mm_subs_epu8(pos, _mm_set1_epi8(-16)); + range2 = _mm_shuffle_epi8(df_ee_table, tmp1); + tmp2 = _mm_adds_epu8(pos, _mm_set1_epi8(112)); + range2 = _mm_add_epi8(range2, _mm_shuffle_epi8(ef_fe_table, tmp2)); + + range = _mm_add_epi8(range, range2); + + /* Load min and max values per calculated range index */ + __m128i min_range = _mm_shuffle_epi8(range_min_table, range); + __m128i max_range = _mm_shuffle_epi8(range_max_table, range); + + /* Check value range */ + if (ReturnPosition) { + error = _mm_cmplt_epi8(input, min_range); + error = _mm_or_si128(error, _mm_cmpgt_epi8(input, max_range)); + /* 5% performance drop from this conditional branch */ + if (!_mm_testz_si128(error, error)) { + break; + } + } else { + error = _mm_or_si128(error, _mm_cmplt_epi8(input, min_range)); + error = _mm_or_si128(error, _mm_cmpgt_epi8(input, max_range)); + } + + prev_input = input; + prev_first_len = first_len; + + data += 16; + } + /* If we got to the end, we don't need to skip any bytes backwards */ + if (ReturnPosition && (data - (end - len)) == 0) { + return ValidUTF8Span<true>(data, end); + } + /* Find previous codepoint (not 80~BF) */ + data -= CodepointSkipBackwards(_mm_extract_epi32(prev_input, 3)); + if (ReturnPosition) { + return (data - (end - len)) + ValidUTF8Span<true>(data, end); + } + /* Test if there was any error */ + if (!_mm_testz_si128(error, error)) { + return 0; + } + /* Check the tail */ + return ValidUTF8Span<false>(data, end); +#endif +} + +} // namespace + +bool IsStructurallyValid(y_absl::string_view str) { + return ValidUTF8</*ReturnPosition=*/false>(str.data(), str.size()); +} + +size_t SpanStructurallyValid(y_absl::string_view str) { + return ValidUTF8</*ReturnPosition=*/true>(str.data(), str.size()); +} + +} // namespace utf8_range diff --git a/contrib/libs/protobuf/third_party/utf8_range/utf8_validity.h b/contrib/libs/protobuf/third_party/utf8_range/utf8_validity.h new file mode 100644 index 0000000000..076c175f6f --- /dev/null +++ b/contrib/libs/protobuf/third_party/utf8_range/utf8_validity.h @@ -0,0 +1,23 @@ +// Copyright 2022 Google LLC +// +// Use of this source code is governed by an MIT-style +// license that can be found in the LICENSE file or at +// https://opensource.org/licenses/MIT. + +#ifndef THIRD_PARTY_UTF8_RANGE_UTF8_VALIDITY_H_ +#define THIRD_PARTY_UTF8_RANGE_UTF8_VALIDITY_H_ + +#include "y_absl/strings/string_view.h" + +namespace utf8_range { + +// Returns true if the sequence of characters is a valid UTF-8 sequence. +bool IsStructurallyValid(y_absl::string_view str); + +// Returns the length in bytes of the prefix of str that is all +// structurally valid UTF-8. +size_t SpanStructurallyValid(y_absl::string_view str); + +} // namespace utf8_range + +#endif // THIRD_PARTY_UTF8_RANGE_UTF8_VALIDITY_H_ |